Category neural network
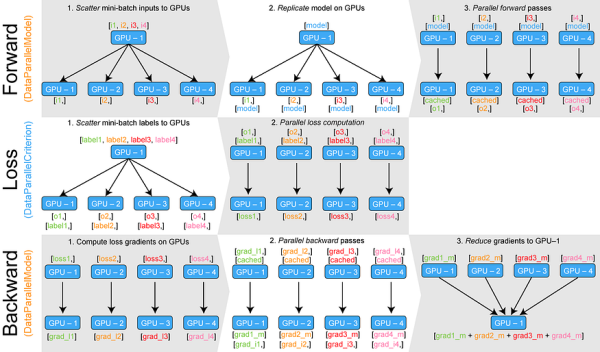
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups… Source: Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups | by Thomas Wolf | HuggingFace | Medium Read… Continue Reading →