Category pytorch
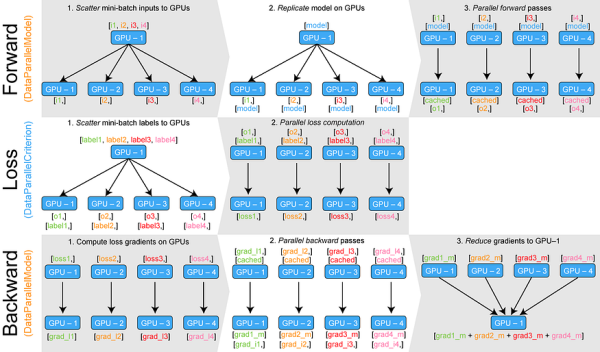
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups… Source: Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups | by Thomas Wolf | HuggingFace | Medium Read… Continue Reading →
Large language models (LLM) are notoriously huge and expensive to work with. An LLM requires a lot of specialized hardware to train and manipulate. We’ve seen efforts to transform and quantize the models that result in smaller footprints and models… Continue Reading →